Graphcore公布最新MLPerf提交结果,超越NVIDIA
日前,MLCommons发布了MLPerf Training v2.0的结果,此次共收录了来自21个不同提交者的250多项性能测试结果,包括Azure、百度、戴尔、富士通、技嘉、谷歌、Graphcore、HPE、浪潮、英特尔-HabanaLabs、联想、Nettrix、NVIDIA、三星和Supermicro。此外,ASUSTeK、CASIA、H3C、HazyResearch、Krai和MosaicML等是首次参加训练测试评估。
Cambrian-AI Research LLC创始人兼首席分析师Karl Freund,在福布斯上发表了一篇题为“NVIDIA丢掉了AI性能王冠,至少目前如此”的文章,评论了此次MLPerf的结果。
Freund表示,这是MLPerf自公布以来,NVIDIA第一次没有横扫全部排行榜。“虽然NVIDIA绝对霸主的时代可能已经结束,但NVIDIA GPU的灵活性和庞大的软件生态系统将继续形成一条又深又宽的护城河。”
与此同时,谷歌、英特尔和Graphcore在跨越这条护城河的尝试中迈出了重要一步:卓越的性能、良好的软件和扩展能力。
日前,Graphcore中国工程副总裁、AI算法科学家金琛和百度飞桨产品团队负责人赵乔向媒体介绍了Graphcore与百度飞桨联合提交的MLPerf测试的最新结果。本次提交中,Graphcore使用新发布的Bow系统分别在图像分类模型ResNet-50和自然语言处理模型BERT上实现了和上次提交相比高达31%和37%的性能提升。此外,Graphcore还新增了语音转录模型RNN-T的提交。
金琛总结了此次Graphcore的三大亮点,分别为:人工智能平台、生态系统以及超越MLPerf。
唯一差异化的平台
此次,Graphcore成功提交今年所发布的Bow系列新品,包括Bow Pod16、Bow Pod64,还包含Bow Pod128、Bow Pod256,“这是Graphcore今年三月刚刚发布的新品,不到数月时间便直接转化为实际的商用化测试。”金琛说道。
金琛特别强调,在众多参与此次MLPerf测试的芯片公司中,Graphcore是唯一有差异化处理器架构的平台。不同于NVIDIA、Google、英特尔等SIMD芯片架构,Graphcore采用的是MIMD架构,这是一种多核分布式、片上内存分布式的多指令多数据架构,因此可以高效解决更复杂的场景。
此外,2021年七月,在MLPerf 1.0提交时,Graphcore使用的是2.1版本的SDK,此次SDK升级到了2.5,从而提升了对不同AI框架的支持,比如TensorFlow、PyTorch和百度飞桨,并且也提供了对高层开源框架的支持,开发者可以通过这些高级的API快速构造模型。
同时,Graphcore还在模型层面对训练过程进行了优化,比如提高训练过程中的验证的效率。
此次的模型提交,Graphcore提供了ResNet-50和BERT两个标准模型测试结果,此外,在语音方面在开放分区提交了RNN-T(Recurrent Neural Network Transducer),这是始于其客户的项目。
令金琛倍感自豪的是,此次Bow Pod在ResNet-50和BERT上取得了巨大进步,并继续超越NVIDIA。Graphcore此次在封闭分区面向ResNet-50和BERT两个模型提交了以3D WoW处理器Bow IPU为核心的Bow系统,包括Bow Pod16、Bow Pod64、Bow Pod128和Bow Pod256。结果显示,与上次提交相比,ResNet-50的训练时间提升高达31%,BERT的训练时间提升高达37%。同时,和前代产品相比,Bow系统在提供更优性能的同时价格保持不变,进一步提升了Graphcore系统的性价比优势。
金琛给出了一组实际测试数据,在GPU占据优势的模型ResNet-50上,Bow Pod16仅耗时19.6分钟,表现优于NVIDIA的旗舰产品DGX-A100 640GB所需的28.7分钟,性能提升大概30%,而在Bow Pod256上,结果显示ResNet-50的训练时间仅需2.67分钟。8台DGX-A100和Bow Pod256相比,性能对比约为6比10,而Bow Pod的价格又远远低于DGX-A100的8倍,这足以证明Graphcore产品相比NVIDIA的高性价比。
除此之外,Graphcore还提交了RNN-T在开放分区中的结果。RNN-T是一种进行高度准确的语音识别的精密方式,在移动设备上被广泛使用。在Bow Pod64上,RNN-T的训练时间可以从原本的几周缩短到几天。
“从IPU-POD16到Bow Pod16,(ResNet-50)的训练时间性能提升了31%,吞吐量的提升约为1.6倍,其中1.3倍来自硬件提升,1.26倍来自软件提升。Bow Pod256提升了接近30%。实际上系统越大,速度越难提升,Graphcore在大尺度的系统上做了很多通信库,做了很多集合通信(collective communication)上的优化,使得在大尺度系统上的表现也有类似的同比例提升。”金琛说道。
共建生态系统
“对Graphcore而言软件生态非常重要,我们花了大量时间和工程师资源来迭代和优化软件,从而更好地接入不同软件框架。从SDK 1.0没有太多生态商的支持,到如今已经可以比较轻松地接入不同的AI框架生态,比如百度飞桨就是一个典型案例。”金琛说道。
“除了NVIDIA之外,Graphcore是为数不多具备足够软件成熟度的芯片公司,这是一个重要的里程碑。”
而此次与飞桨联合提交的MLPerf结果,也印证了金琛所说的软件生态的成果。“PopART是Graphcore自研的框架,是基于芯片所构造的高效的训练推理引擎,百度飞桨使用Bow Pod16和Bow Pod64进行了BERT在封闭分区的提交,结果与Graphcore使用PopART进行提交的结果几乎一致,一方面证明我们的软件栈非常成熟,能够快速对接一个新的AI框架。另一方面也证明了百度飞桨的框架非常高效。”
赵乔则从飞桨的角度,详细介绍了双方的合作关系。
在硬件合作方面,百度飞桨目前在全球的三大框架内,是唯一一个在积极地接收各家厂商代码的框架,并且建立完备的CI和CE的技术栈,从而确保所有硬件合作伙伴的代码能跟着百度飞桨的主干代码进行升级,而TensorFlow和PyTorch目前是只有一条A类型代码。
此外,除了底层的核心框架以外,百度飞桨作为一个深耕产业级应用的平台,在上层的技术模型库和以模型为特色的一些领域的端到端开发套件上,采取了自底层开始搭建神经网络应用的方法。因此,也建立了一系列的套件,比如文字识别、图像分割、目标检测、NLP和语音等等,这些套件无论在GitHub上还是Gitee平台上,都受到了国内以及全球开发者的喜爱。这也是飞桨能够和硬件厂商达成快速合作的重点,因为这些套件能够帮助硬件厂商的开发者降低开发和部署门槛。
百度飞桨于2020年正式开启与硬件厂商的合作,同包括Graphcore在内的13家国内外顶级的企业,一起成立了百度飞桨的硬件生态圈。2021年围绕飞桨的硬件生态圈开展了众多技术联合优化工作,并针对百度飞桨进行大量框架层面上的改造,让硬件厂商和百度飞桨更好地对接、适配、优化。
2022年则正式发起了硬件生态共创计划,帮助硬件厂商一起建设自己的AI软件生态系统。“硬件厂商可能更侧重于底层的软件栈、开发体验。百度飞桨作为上层的AI应用框架平台,对于应用非常了解,无论是提供更好的Model Zoo,或者提供更好的上层应用开发工具,都能跟厂商的软件栈进行紧密地协同。”赵乔说道。
通过合作,Graphcore给了飞桨很多新思路。赵乔举例道,飞桨早期的方案主要是进行类似算力开发、映射的工作,主要对接包括像NVIDIA的CUDA或者AMD的ROCm这样的软件栈。由于这几年各类型的硬件厂商非常多,每个厂商采用不同的软件栈,所以飞桨只能不断增加与硬件厂商对接的技术方案。而Graphcore的合作则是以子图或者整图的方式,跟硬件厂商做高效率对接。“Graphcore是首家在训练场景中和飞桨对接的硬件厂商,飞桨花了半年时间对框架进行改造,从而以整图方式与硬件厂商对接,最终成果是基于PopART的成绩和基于飞桨的成绩,其性能是一致的。”
金琛也表示,PopART是Graphcore自研的底层训练推理框架,比起直接使用PopART,Graphcore更希望利用诸如飞桨等框架,在IR层和PopART进行对接,可以直接面向AI算法工程师或者AI应用开发者。
赵乔表示,百度是MLPerf最早的发起单位之一,飞桨可以为更多硬件厂商提供支持,包括技术层面的对接,联合针对MLPerf进行优化,以及最终完善AI生态共创计划,并基于MLPerf成果进行产品转化和应用推广等工作。
超越MLPerf
金琛表示,提交MLPerf的成绩固然对Graphcore意义重大,但Graphcore更希望把算力转化为客户价值。MLPerf的模型集合是在2018年就制定了,且最新的模型只有BERT。但客户是非常超前的,比如2021年发表的关于Swin Transformer模型获得了ICCV最佳论文,今年便已实际应用在国内。“我们希望把客户对于我们的需求转化为我们训练模型能力,因此除了MLPerf打榜之外,我们更注重我们对于客户的价值体现。”金琛表示。
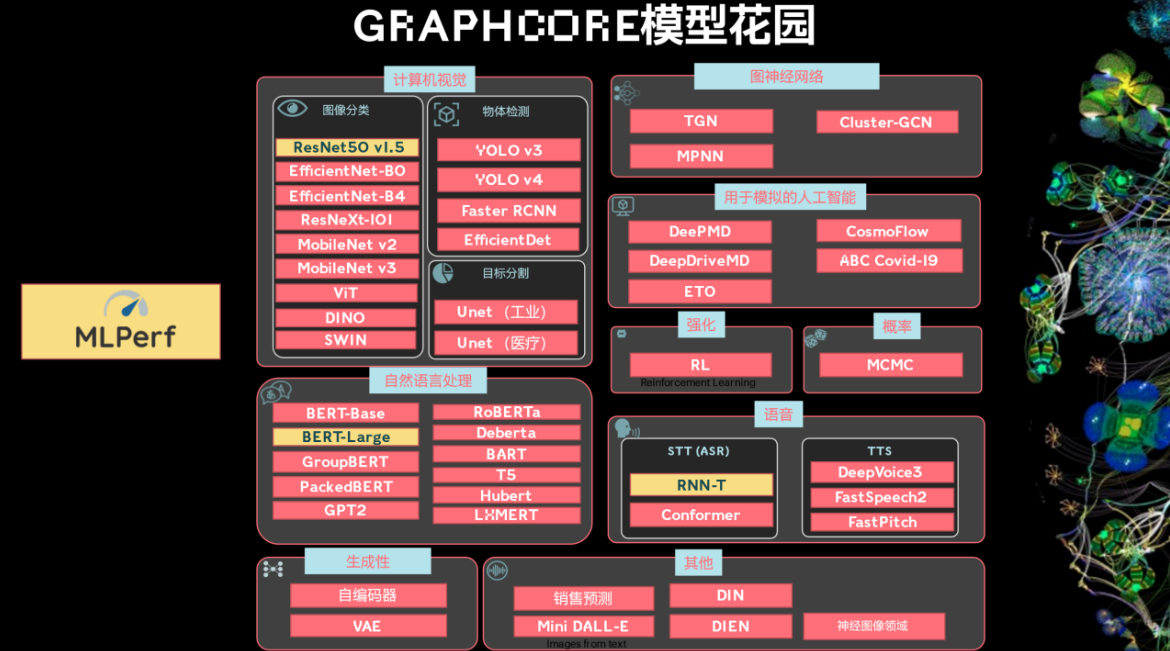
黄色图标代表Graphcore历届提交的MLPerf模型,而红色图标则是Graphcore客户的模型需求,可以看出MLPerf只占到实际应用的一小部分。实际上,Graphcore的客户已经涵盖了图像分类、物体检测、目标分割、自然语言处理、生成性、语音、强化学习、用于模拟的人工智能等诸多领域的新兴模型,甚至还包括了HPC、分子动力学、销售预测。
也正因此,此次在MLPerf上,Graphcore提交了RNN-T,这诞生于其美国一个客户Gridspace,是一家关注客服流程自动化及语言训练的公司。Gridspace想利用的模型是Transformer-Transducer,是RNN-T的一个变种,将原来的LSTM的backbone换成Transformer的backbone。最终,客户通过拓展模型在Bow Pod64上运行,使该数据集上的训练时间从几周减少到只需要几天。
Graphcore也与Twitter合作,证明了其在图神经网络上的提升,相比A100实现了两倍至10倍的时间节约。另外,包括与Pacific Northwest在分子动力学上的合作,以及与Tractable在EfficientNet计算机视觉上的合作等实际案例中,Graphcore的成绩均好于NVIDIA。
关于未来的路线图
关于未来,金琛提到了Graphcore打造的Good Computer(古德计算机),这是为数百万亿的参数量的模型而定制的计算机,具有8192个路线图IPU,能够提供超过10 Exa-Flops的AI算力,具有10 PB/s的内存带宽。
而更落地的项目,则是Graphcore将与飞桨继续开展深入合作。赵乔表示希望在百度智能云或者外部的商业用户中更多看到基于飞桨与Graphcore的整体方案。同时双方也会在生物制药等方面,进行紧密探讨。
金琛则表示,在Graphcore的模型花园中,希望支持飞桨原生动态图,并会原生对接新开发的像PopIT、PopIR以及后端的一些新的执行模式。
“在模型层面,飞桨的外延生态很大,比如PaddleNLP、PaddleCV等等。我们最近在跟PaddleNLP进行对接,做了很多语言模型方面的扩充。我们也希望在视觉上可以进一步合作,让大家快速体会到飞桨和新硬件的优势。”金琛说道。
