微软推出VALL-E,只需3秒音频训练即可模仿人说话
科技巨头微软研究人员推出了最新的文本到语音 (TTS) 生成器VALL-E,可以在短短三秒钟内训练模仿任何人的声音。与以前听起来像机器人的语音发生器不同,VALL-E 听起来很自然,这可能不是一件好事。
谷歌、Meta 等主要科技公司也一直致力于这一领域,以使其产品更易于使用。然而,这些产品并非旨在模仿用户的声音,需要无数小时的培训才能做到这一点,而且效果不佳。获取更多科技前沿请访问:https://byteclicks.com
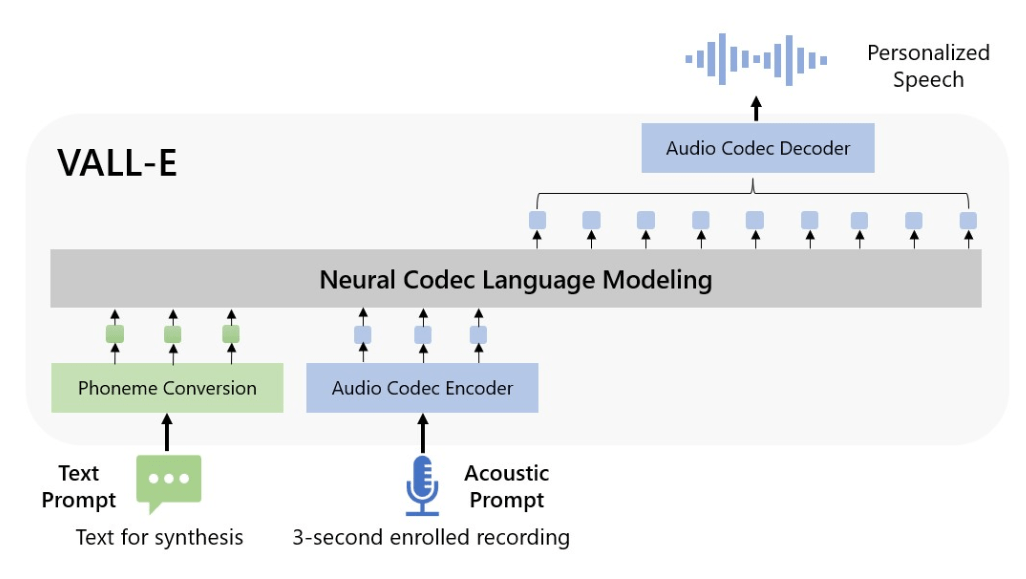
VALL-E令人难以置信的能力
传统的 TTS 生成器依靠操纵波形来合成语音。与目前的许多人工智能工具不同,VALL-E 可以复制说话者的情绪和语气,即使说话者本人从未说过的单词也可以模仿。
研究团队声称,音频样本可以短至三秒,这足以让 VALL-E 完成工作。这使得 VALL-E 成为零样本 TTS 生成器。
VALL-E 的训练是使用 LibriLight 进行的,LibriLight 是一个由 Meta 整合的音频库,包含来自公共领域 LibriVox 有声读物的近 60,000 小时英语演讲。
VALL-E 成功的做法是将三秒钟的音频样本与它训练过的 7,000 人之一的声音进行匹配,然后以与训练数据中与之相似的声音传递文本,以提供准确的模仿响应。
微软声称,VALL-E 不仅可以模拟电话等声学环境中的声音,还可以根据说话者提示中的情绪进行语音表达,更加个性化和自然。
OpenAI 的另一款产品DALL:E可根据文字描述自动生成图片,现在微软的技术可以在未来的电影中重现已故演员的声音。
不过对于该技术未来可能存在的技术漏洞、技术滥用等风险也不容忽视。
目前,AI技术的落地应用,正在不断打通虚拟世界和现实世界的界限,我们需要思考的是,如果未来这些技术越来越强大和普及,明辨真假将会变得越来越困难,技术发展的同时又该如何把控安全隐患问题?
版权声明:除特殊说明外,本站所有文章均为 字节点击 原创内容,采用 BY-NC-SA 知识共享协议。原文链接:https://byteclicks.com/45265.html 转载时请以链接形式标明本文地址。转载本站内容不得用于任何商业目的。本站转载内容版权归原作者所有,文章内容仅代表作者独立观点,不代表字节点击立场。报道中出现的商标、图像版权及专利和其他版权所有的信息属于其合法持有人,只供传递信息之用,非商务用途。如有侵权,请联系 gavin@byteclicks.com。我们将协调给予处理。
赞
